Project Westdrive LoopAR
Visit projectVirtual reality experiment studying the effectiveness of auditory, visual, and multimodal takeover requests in autonomous driving scenarios.
VR Toolkit for Takeover Requests in Semi-Autonomous Driving
Background / Problem
Current SAE Level 3 systems still require the human to take over when the vehicle reaches its operational limits. In practice this is fragile: drivers are often out of the loop — they are doing a non-driving task, their gaze is off the road, and they have to (1) notice the request, (2) reorient to the outside world, (3) identify the hazard, and (4) execute a motor response — all inside the 4–8 s takeover window that many systems assume is “enough.” Your argument in LoopAR was: that window is only sufficient if the driver already knows where to look. If they first have to find the dangerous object, they lose exactly the seconds that make the difference between an avoided crash and a collision. LoopAR was built to test this directly by comparing four human–machine interface (HMI) conditions: no signal, audio only, visual only, and audio–visual combined.
Core Idea
Instead of a static driving simulator, LoopAR is a mobile, open-access VR pipeline that reproduces takeover situations in a realistic, controllable, and repeatable environment. It extends the earlier Westdrive city (urban AV acceptance study) into a longer, more varied road network based on real OSM data (Baulmes / Swiss Alps region), so you can test TORs not only in one street scene but in four road ecologies: mountain, country, highway, and town. This matters, because takeover difficulty depends on visibility, speed, and traffic complexity.
Approach
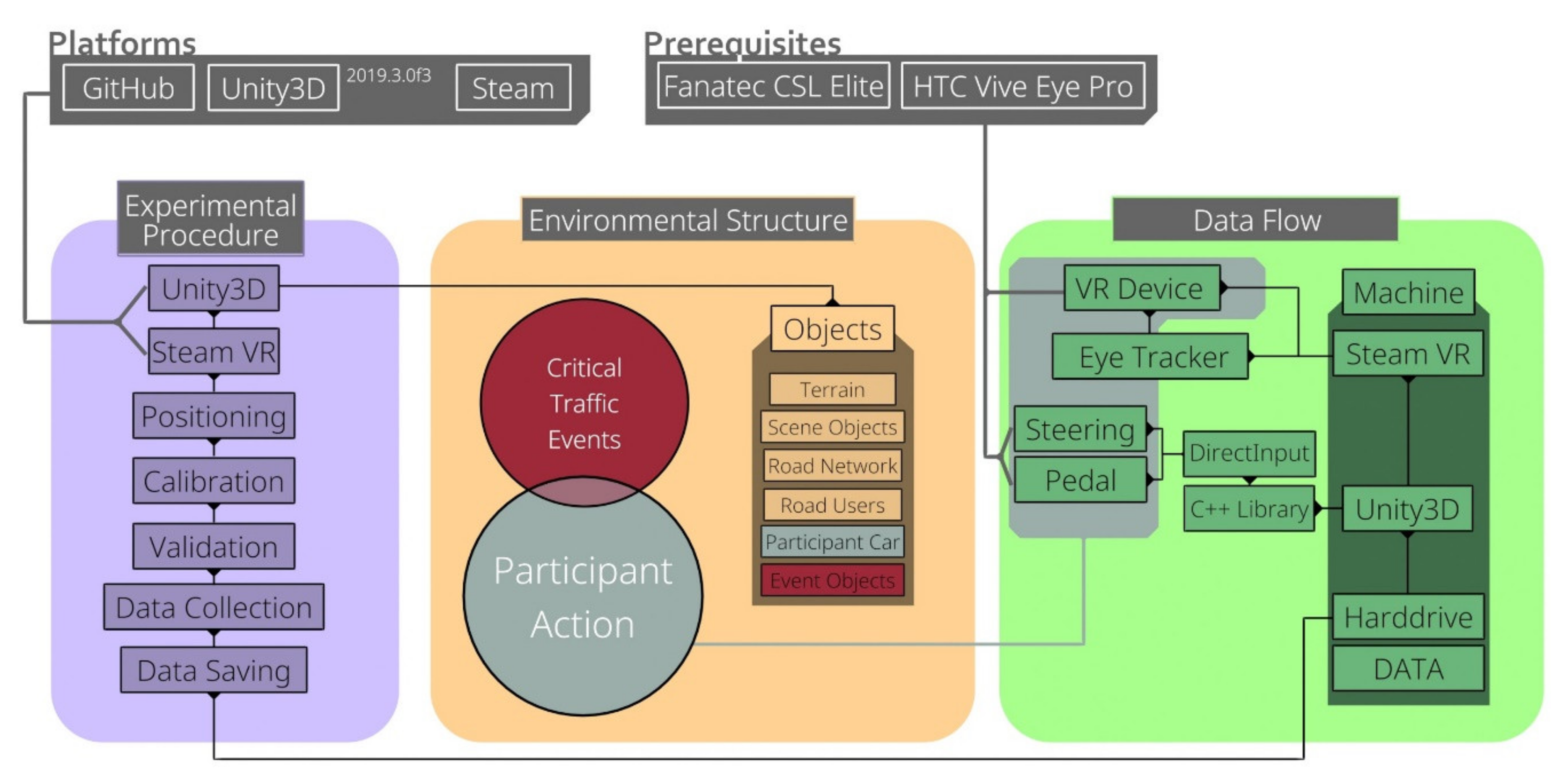
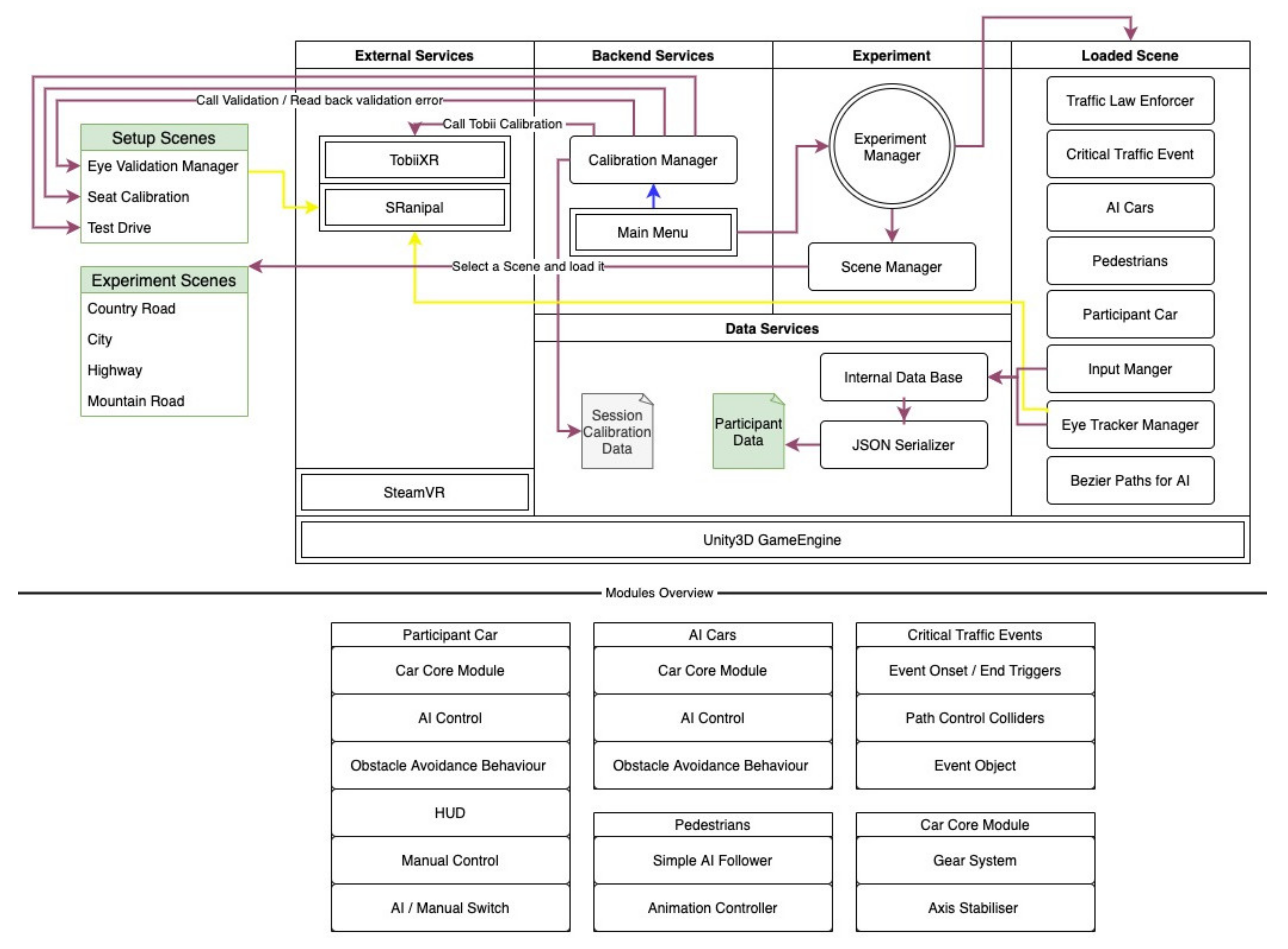
1. Environment & Rendering
- Base: Unity 2019.3, C# MonoBehaviour, modular prefabs.
- Terrain: ~25 km², ~11 km continuous drive, four scenes (mountain, city “Westbrück”, country, highway). All derived from OpenStreetMap, cleaned in Blender.
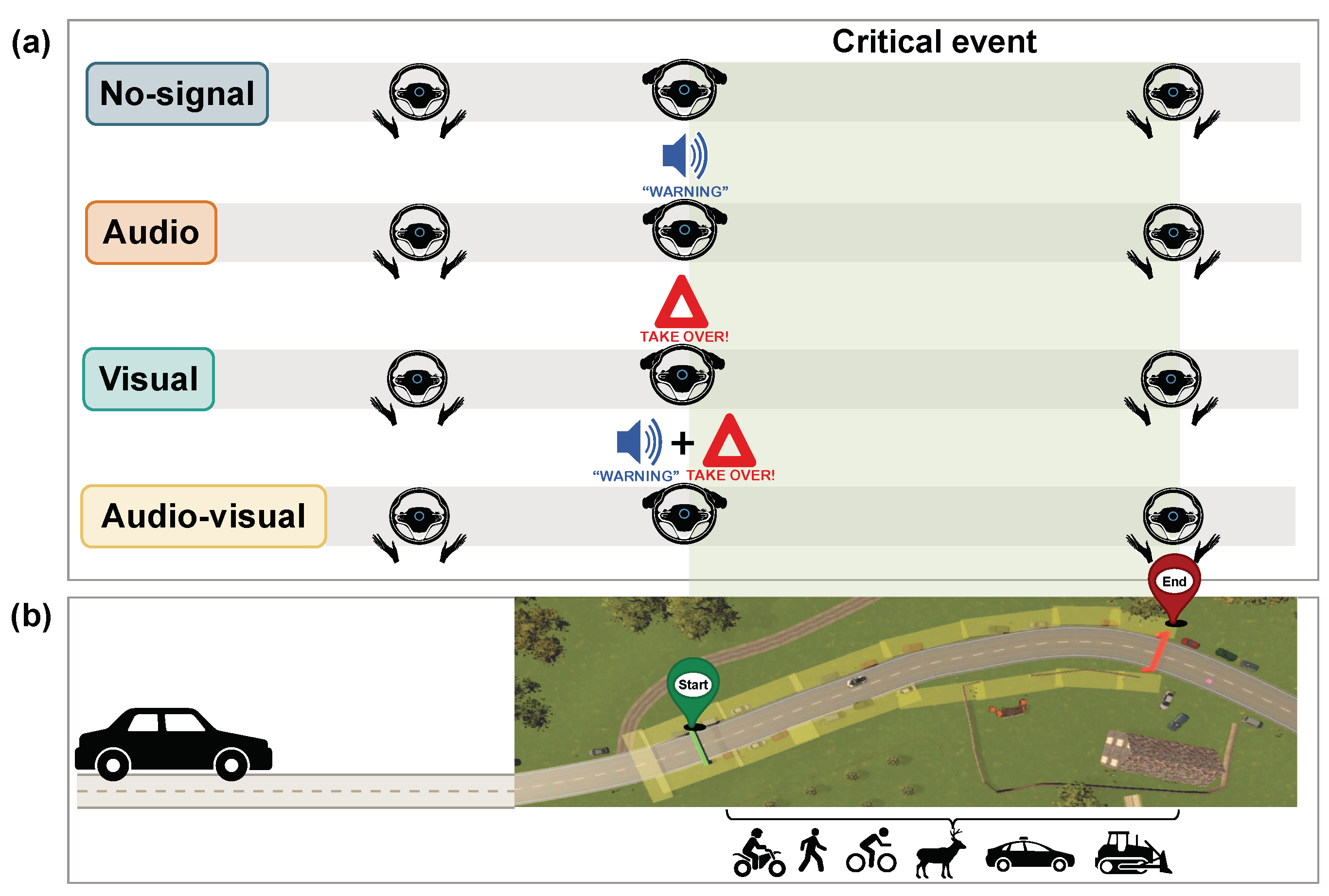
- Population: AI cars (motorbikes, trucks, cars), 125 animated pedestrians, traffic signs compliant with German StVO to keep scene lawful and interpretable. Critical events were designed in consultation with a former German police officer so they reflect typical German accident causes (child/pedestrian, obstacle in lane, vehicle pulling out, landslide/animal on mountain road).
- Performance: LODs, baked lighting, texture atlases → stable ~88–90 FPS on Vive Pro Eye, i.e. at the sampling rate of the eye tracker. This is important, because you measured gaze-on-hazard at video framerate; frame drops would have corrupted the “dwell time” metric.
2. Vehicle & Event Logic
- Unlike Westdrive, LoopAR used physics-based cars (Unity wheel colliders) so that manual takeover actually felt like driving and so that steering/brake reaction time could be treated as a meaningful motor signal.
- Paths for AI traffic were generated with your in-house Bézier solution, wrapped in a modular event system: every critical event is just a prefab with start trigger → hazard spawn/highlight → boundary triggers → respawn. That’s how you turned the whole thing into an open tool other labs can reuse.
- You added a C++ DirectInput bridge so Unity could access force feedback on Fanatec wheels; that’s nontrivial because it keeps haptic cues consistent with the visual takeover request.
3. HMI / AR Windshield
The key experimental manipulation lives in the AR windshield display you rendered in VR:
- No signal: vehicle requests takeover but gives no explicit pointer to the hazard → baseline “out of the loop.”
- Audio: female voice, normal speech rate, “Warning” → designed to test urgency without spatial info.
- Visual: red triangle + red highlight around the object that actually causes the danger, rendered directly in front of the participant on the windshield → this gives spatial binding (“look here”).
- Audio–visual: both at once → your hypothesis: should be best because audio grabs attention, visual solves localization.
This is exactly what you later describe in the Sensors technical note as “freely programmable AR feature in the windshield.”
4. Data & Config
You standardized JSON serialization for:
- per-run config (which scene, which devices active, which TOR delay),
- per-event data (timestamp of signal onset, hands-on-wheel, steering angle, brake/accel),
- per-frame gaze raycast (eye position → collider hit → object name, plus 5 closest objects to reduce search). This became the group’s internal standard and made the later Vehicles 2024 analysis straightforward because everyone exported the same structure.
Experimental Procedure
- Public data collection (fairs in Osnabrück): 250+ participants → large, heterogeneous, non-lab sample.
- Calibration: Vive Pro Eye → Tobii XR SDK → SRanipal; validation failed if error > 1.5°. You dropped those subjects later.
- Each participant drove the same 12 critical events in the same order but with one warning modality (between-subjects), so you could attribute differences in success to modality, not event order.
- Training scene upfront to teach the meaning of the takeover display (otherwise visual condition would be unfair).
- Optional AVAM questionnaire at the end to relate behavior to trust/anxiety.
What You Measured
-
Reaction time
You didn’t just log “first movement.” You decomposed it per effector (steering, brake, accel), smoothed the rate of change, detected the first local maximum > threshold, and defined:- fastest RT = min(steer, brake, accel)
- expected RT = the one that fits the event (e.g. steering for lane obstruction, brake for frontal hazard).
This lets you say “visual warnings reduce the RT that actually matters for this event.”
-
Situational awareness
You used eye tracking the way it should be used in VR: “did the gaze ray actually hit the object of interest?” → binary “seen/not seen,” plus count of hits, plus total dwell time (only >100 ms fixations kept). That gave you a quantitative awareness index per event. All hazards had colliders, so the raycast was exact. -
Task success
Unity already knew whether the participant hit a boundary trigger → so “success” = got through event without collision. This allowed logistic regression with predictors: modality, seen_OOI, RT, dwell_time. That’s the analysis you reported: any warning ↑ success, and seeing the hazard ↑↑ success, and visual/audio-visual amplified the effect of dwell time. -
Acceptance (AVAM subset)
You ran EFA and found two factors: (1) anxiety/safety/trust, (2) control preferences (eye/hand/feet). Then MANOVA → all signal conditions did better than no-signal on the anxiety/trust factor. That’s a neat extra: good HMIs don’t just make drivers faster, they make them less anxious about automation.
Findings
From the 2024 Vehicles paper and the 2021 Sensors tech note, your results line up very cleanly:
- No-signal is worst: lowest success, slowest RT, lowest dwell on the hazard. So the “8 seconds is enough” assumption breaks for inattentive users.
- Visual and audio–visual both significantly reduced reaction time compared to baseline; audio alone did not. Vision gives immediate spatial binding → driver knows where to look.
- Any warning (even audio) increased dwell time on the hazard → attention was successfully recaptured.
- Best condition = audio–visual: urgency + location → highest success probability in the logistic model.
- Success was not just “react fast”: the model showed that short RT + high dwell together predict success, and visual / AV signals strengthen exactly that interaction. That’s an important nuance: the HMI is helping reconstruction of the scene, not just reflexes.
- Questionnaire: all warning conditions reduced anxiety and increased trust vs baseline — so adding these HMIs helps with acceptance, which was the original Westdrive theme.
Why LoopAR Matters
- It turns takeover-request research into something portable and repeatable — you don’t need a €200k fixed-base simulator.
- It gives a shared data format (JSON) and an open Unity scene so other labs can replicate exactly your 12 critical events.
- It shows, with eye-tracking to back it up, that visual or multimodal HMIs are not UX candy — they are safety-relevant. The car must tell you what the danger is, not only that there is danger.
Your Role
- Defined the research question (is 8 s enough if driver has to search for hazard?)
- Architected the Unity project (scene loading, modular events, AR windshield)
- Implemented hardware integration (Vive Pro Eye, Fanatec, C++ DirectInput)
- Designed the JSON data/Config standard later used by the whole group
- Managed the 9-person dev/research team with Agile/Scrum
- Ran pilots and exhibition deployments with robust remote monitoring (same infra as Westdrive)
- Performed/assisted statistical analysis (RT extraction, logistic regression, MANOVA)
- Co-authored the open-access publications describing LoopAR and its code base
References
- Huang, A., Derakhshan, S., Madrid-Carvajal, J., Nosrat Nezami, F., Wächter, M. A., Pipa, G., & König, P. (2024). Enhancing safety in autonomous vehicles: The impact of auditory and visual warning signals on driver behavior and situational awareness. Vehicles, 6(3), 1613–1636. https://doi.org/10.3390/vehicles6030076
- Nosrat Nezami, F., Wächter, M. A., Maleki, N., Spaniol, P., Kühne, L. M., Haas, A., … Pipa, G. (2021). Westdrive X LoopAR: An open-access virtual reality project in Unity for evaluating user interaction methods during takeover requests. Sensors, 21(5), 1879. https://doi.org/10.3390/s21051879