iVISPAR
Visit projectDeveloped an interactive visual-spatial reasoning benchmark using Unity3D and networking solutions to evaluate vision-language models and human participants.
Scene Understanding Puzzle Benchmark
Problem
Although large language models (LLMs) have demonstrated extraordinary capabilities in language understanding and multimodal reasoning, their true comprehension of visual scenes and ability to strategically solve spatial problems remain underexplored. While benchmarks exist for text-based reasoning, few systematically evaluate how VLLMs (Vision-Language Models) handle scene-based reasoning, where perception, spatial awareness, and action planning converge.
To investigate this gap, we designed a novel benchmark that directly compares state-of-the-art VLLMs with human participants in solving structured, manipulable puzzles. This setup allows us to quantitatively and qualitatively evaluate how well these models can interpret visual inputs, plan multi-step actions, and adapt to complex 3D spatial challenges.
Approach
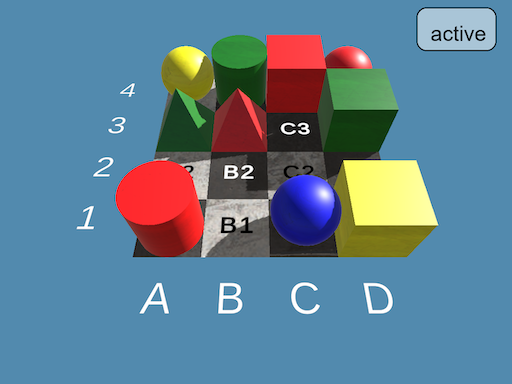
The benchmark is built upon a Unity3D environment featuring two distinct sliding tile puzzles designed to test hierarchical reasoning, object manipulation, and spatial awareness. The choice of a three-dimensional implementation was deliberate: by incorporating depth and occlusion, we expose the models to realistic perceptual ambiguities that traditional 2D benchmarks often neglect. These challenges are central to understanding how VLLMs perceive and interpret partially visible or dynamically changing scenes.
To enable seamless communication between the LLMs and the Unity environment, I developed a WebSocket-based networking architecture using Python. This system operates as an intermediary server, translating model-issued commands into environment-level actions and returning state updates to the model. Through this framework, both experimenters and models can send JSON-formatted instructions, such as initializing new puzzles, resetting configurations, or performing object transformations (e.g., moving or rotating puzzle tiles).
After every action, the Unity environment captures and transmits a high-resolution screenshot of the current puzzle state. This feedback loop enables LLMs to reason iteratively, forming hypotheses about the next optimal action based on evolving scene information.
To complement the visual task, we also created a fully text-based version of the puzzles, allowing the same reasoning pipeline to be evaluated in a symbolic context. This dual setup — one grounded in visual perception and the other in abstract textual representation — allows us to assess the extent to which multimodal reasoning truly enhances problem-solving performance.
Results
(Refer to related publications for empirical findings, comparative performance analyses, and behavioral insights between human participants and VLLMs.)
My Role
- Unity3D Development: Designed and implemented the 3D sliding tile puzzles, focusing on realistic spatial mechanics, depth handling, and occlusion effects to increase ecological validity.
- Networking Architecture: Developed a full WebSocket server-client system in Python and C#, enabling synchronous communication between multiple experiments and LLM instances in parallel.
- System Programming: Implemented the underlying control logic for object manipulation, camera management, and real-time state synchronization between Unity and external clients.
- File Server Management: Built a dedicated file hosting service for storing and serving puzzle setup configurations, ensuring rapid and consistent experiment initialization.
- Server Administration and Security: Handled server deployment, including SSL certificate generation and renewal to secure data transmission and WebSocket communication.
- Infrastructure Configuration: Configured the Nginx reverse proxy for request routing, load balancing, and HTTPS enforcement.
- Experimental Design Support: Contributed to the conceptualization and experimental design, assisting in defining the evaluation criteria, model interaction protocols, and data collection pipelines.
This benchmark represents a step toward understanding how multimodal AI systems reason about the world beyond text — bridging the gap between linguistic intelligence and embodied spatial reasoning.